
La « datascience », ou science de la donnée, évoque plus une discipline à part entière qu’un outil parmi d’autres dans l’ingénierie logicielle. Et pourtant, l’équipe Mes Aides l’utilise aussi pour améliorer l’expérience de ses utilisateurs !
Mes Aides est le plus ancien produit grand public de l’Incubateur de services numériques. Accessible depuis le mois d’octobre 2014, c’est le candidat parfait pour explorer des données réelles. Avec l’aide de Florian Gauthier, data scientist de la mission Administrateur général des données, nous avons cherché à mieux comprendre les situations les plus simulées afin de nous améliorer.
En analysant ces données, nous souhaitions être mieux équipés pour :
Pour rappel, les situations que nous enregistrons ne contiennent aucune information nominative. L’intégralité des manipulations effectuées est disponible dans un notebook iPython.
Les communes où Mes Aides est le plus utilisé sont les communes les plus peuplées. Sur la carte ci-dessous, plus la couleur est foncée, plus l’usage est important. Cela laisse donc supposer que la diffusion de l’usage est homogène sur le territoire.
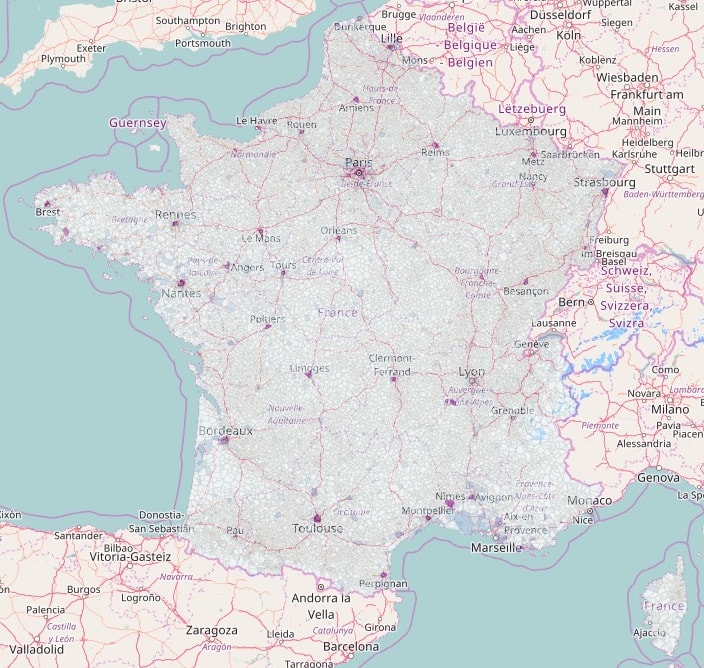
Contrairement à une idée reçue, on n’observe pas de corrélation significative entre pauvreté et usage de Mes Aides (pour un indicateur habituel de pauvreté qu’est la médiane du revenu disponible par unité de consommation).
Une exception à ce constat est la région Île-de-France.
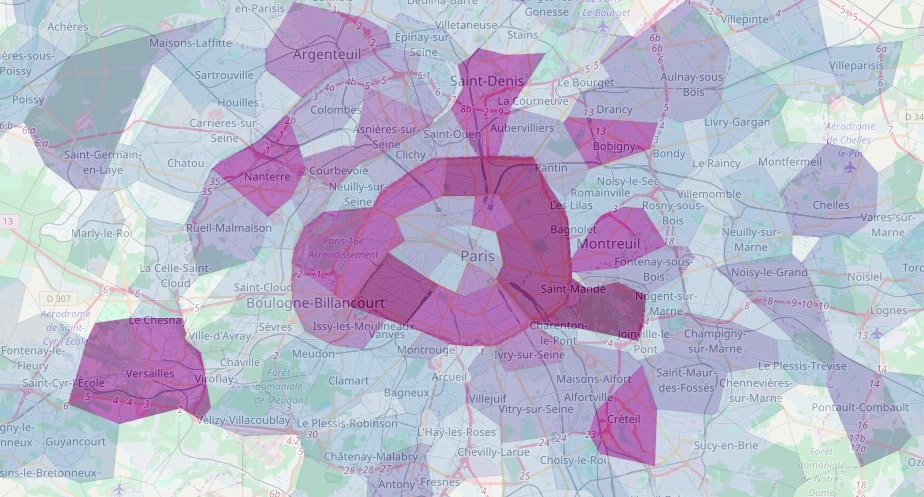
Nous faisons l’hypothèse que cette répartition spécifique de l’usage est liée à nos partenariats, notamment le CASVP et le département du 93. Cela est également cohérent avec l’usage volontariste que fait le CCAS de Versailles du simulateur : cette zone n’est pas connue pour avoir une part de population précaire comparable aux autres communes qui utilisent pourtant autant Mes Aides.
L’usage du simulateur reflète aujourd’hui plus certainement l’activité des médiateurs de l’action sociale que directement les besoins de la population générale. Nous sommes heureux et fiers de voir que cet outil remplit sa promesse de servir aussi bien le grand public que les professionnel·le·s du secteur social.
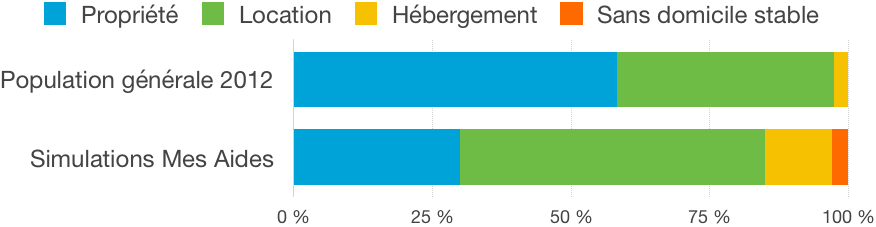
On peut comparer les types de logements simulés dans Mes Aides à la répartition de l’INSEE en 2012. Cette répartition concerne le parc des résidences principales, et ne comprend pas les personnes sans domicile stable.
On voit bien la différence de répartition entre locataires et propriétaires. Afin d’accélérer la navigation des utilisateurs, nous faisons le choix d’ordonner dans l’application les options de type de logement pour que le sens de lecture corresponde aux usages les plus fréquents.

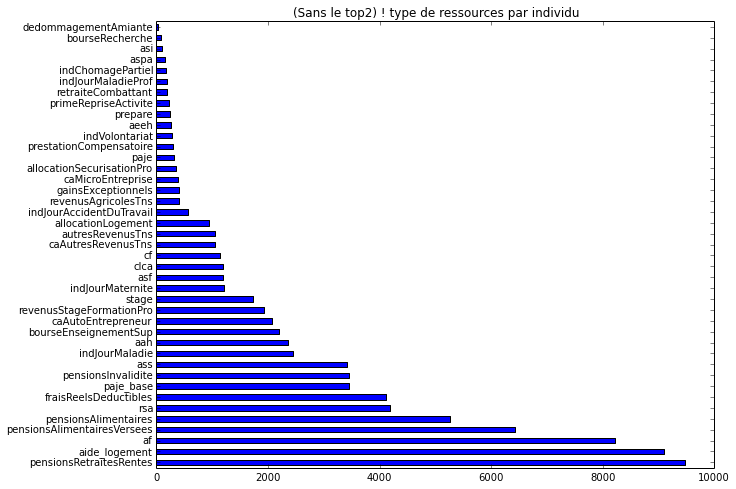
La grande majorité des visiteurs perçoit des salaires, ou un revenu de remplacement du salaire : chômage ou retraite. Ensuite seulement apparaissent les allocations (logement, familiales…), puis d’autres ressources.
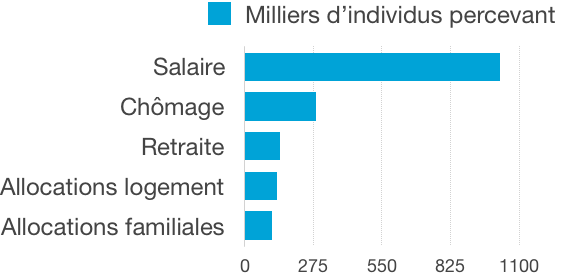
L’application propose actuellement de sélectionner les ressources d’après leur catégorie. Ces données nous orientent à penser une prochaine évolution avec une suggestion « hors catégorie » des ressources les plus fréquemment renseignées.
Les revenus totaux sont en grande majorité nuls dans les situations simulées. On observe un second pic aux alentours du SMIC annuel, puis une décroissance exponentielle vers les hauts revenus.
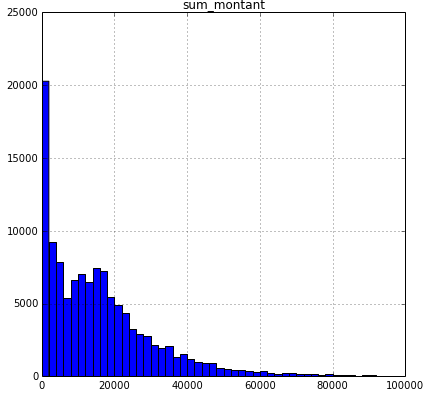
Bien évidemment, plus une personne est en situation de précarité, et plus elle a intérêt à faire un point sur les aides sociales dont elle peut bénéficier.
Cependant, toutes les aides ne sont pas conditionnées par les ressources. Les allocations familiales, par exemple, sont modulées depuis 2016, mais non conditionnées. Une des sources du non-recours est justement de croire à tort que la solidarité nationale ne nous concerne pas. D’ailleurs, avez-vous calculé vos droits ? ;)
Ces statistiques descriptives nous outillent pour mieux comprendre les usages et nous assurer que nous remplissons des objectifs intermédiaires, comme par exemple la diffusion territoriale.
Je vous encourage à utiliser ce type de données d’usage pour optimiser l’interface afin de faciliter le parcours pour les cas les plus fréquents. Il est également possible, au-delà des parcours les plus fréquents, d’effectuer une analyse par partitionnement (clustering) pour optimiser le parcours en faisant des hypothèses sur les saisies les plus probables à partir des premières données.
En revanche, il ne faut pas confondre statistiques descriptives et mesure d’impact : analyser les usages courants est un outil puissant pour les optimiser, mais ne permet pas nécessairement de prouver qu’on répond à un véritable problème. Ce n’est qu’en conjuguant pensée tactique et pensée stratégique que votre produit aura un impact positif sur le réel.
Dans notre cas, en parallèle des améliorations continues que nous menons et de notre travail qualitatif d’appréciation de l’impact sur le terrain, une étude précise de l’impact de Mes Aides sur le non-recours du grand public est en cours, sous l’égide du Poverty Action Lab, un laboratoire de recherche indépendant, en partenariat avec Pôle emploi et la DGCS. Le but : déterminer si les populations ayant utilisé Mes Aides ont statistiquement obtenu plus de prestations sociales que celles qui ne l’ont pas fait. Selon leur représentativité, nous espérons pouvoir nous appuyer sur ces résultats pour extrapoler une mesure d’impact globale de Mes Aides.
Cette analyse est basée sur des données recueillies entre avril 2015 et mai 2016. Nous avons retiré de l’échantillon :
Afin de valider les données obtenues avec les usages observés de Mes Aides, nous avons confronté nos statistiques de fréquentation mesurées sur Piwik avec le nombre de simulations calculées sur Mes Aides. Même si tous les visiteurs arrivant sur la page d’accueil ne vont pas nécessairement faire une simulation, on suppose que la fréquentation devrait être similaire.
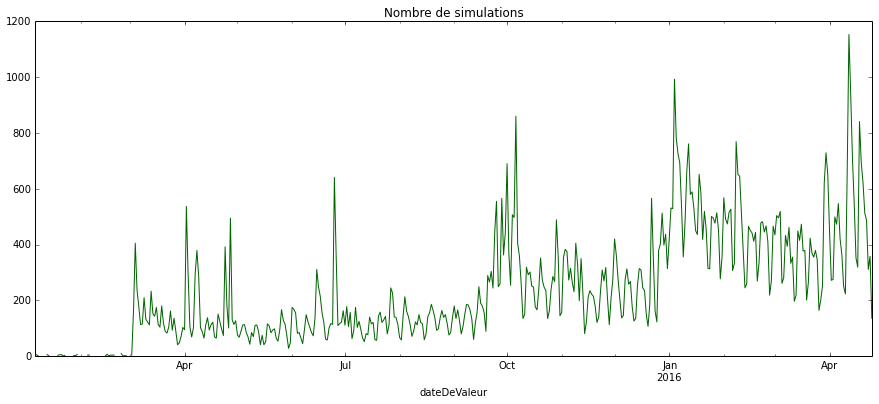
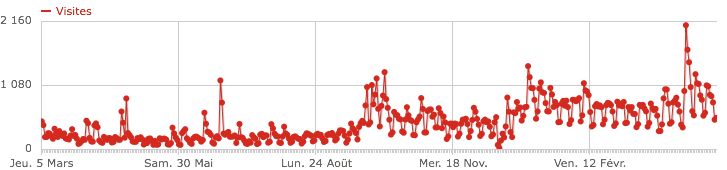
Les données sont bien cohérentes temporellement.
Il est important de garder à l’esprit que les données enregistrées par le simulateur sont purement déclaratives. Les usagers sont encouragés à s’en emparer comme d’un outil de prospective en simulant des situations futures probables. De même, de nombreux professionnel·le·s confrontés pour la première fois à cet outil font des simulations fictives.
Aucune situation individuelle ne peut donc être considérée comme reflétant une situation réelle. En revanche, nous considérons que les tendances qui se dégagent de l’analyse statistique sont représentatives des usages et des usagers de Mes Aides.
Cette étude est basée sur une cohorte de plusieurs dizaines de milliers de demandeurs d’emploi identifiés individuellement par Pôle emploi. Contactés par email, les personnes volontaires sont invitées à se connecter à Mes Aides à travers un lien spécial. Leur parcours sur le site est alors suivi individuellement dans une base de données séparée.
Cette base de données, opérée par le Poverty Action Lab, n’est accessible qu’à ses agents et sera détruite après 36 mois. Vous pouvez auditer le code de suivi qui transmet les données des situations à cette base de données.
Suite à cette étude, Pôle emploi fera une demande au Registre National Commun des Prestations Sociales (RNCPS) pour chacune des personnes ayant participé à l’étude.
Nous publierons un article dès que nous en aurons reçu les résultats finaux.


{kind=link}